Table of Contents
In this chapter, a general overview is given of the architecture of the XT transformation tools. The technical details of the tools and languages that are involved will be discussed in the follwing chapters.
XT is a collection of components for implementing transformation systems. Some of these components generate code that can be included in a transformation system, such as a parser or pretty-printer. Other components can be used immediately, since they are generic tools. The components of XT are all executable tools: they can be used directly from the command-line.
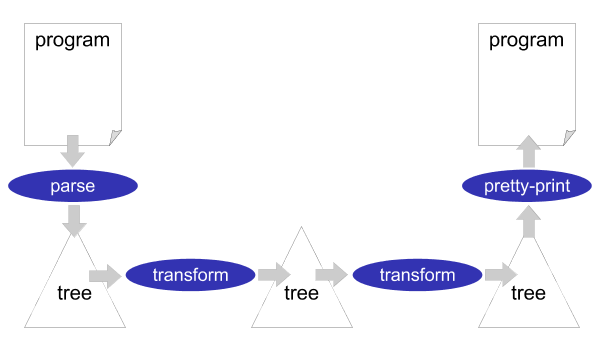
According to the Unix philosophy, the tools that are part of XT all do just one thing (i.e. implement one aspect of a transformation system) and can be composed into a pipeline to combine them in any way you want. A sketch of a typical pipeline is shown in Figure 3.1. First, a parser is applied to a source program. This results in an abstract syntax tree, which is then transformed by a sequence of transformation tools. Finally, the tree is pretty-printed back to a source program. So, this pipeline is a source to source transformation system. The tools that are part of the pipeline exchange structured representations of a program, in the form of an abstract syntax tree. These structured representations can be read in any programming language you want, so the various components of a transformation system can be implemented in different programming languages. Usually, the real transformation components will be implemented in Stratego.
Of course, some compositions are very common. For example, you definitly don't want to enter the complete pipeline of a compiler again and again. So, you want to pre-define such a composition to make it reusable as single tool. For this, you could of create a shell script, but option handling in shell scripts is quite tiresome and you cannot easily add composition specific glue code. To solve this, Stratego itself has a concise library for creating compositions of transformation tools, called XTC. We will come back to that later in Chapter 28.
The nice thing about this approach is that all the tools can be reused in different transformation systems. A parser, pretty-printer, desugarer, optimizer, simplifier, and so an is automatically available to other transformation systems that operate on the same language. Even if a tool will typically be used in a single dominant composition (e.g. a compiler), having the tool available to different transformation systems is very useful. In other words: an XT transformation system is open and its components are reusable.
Programmers write programs as texts using text editors. Some programming environments provide more graphical (visual) interfaces for programmers to specify certain domain-specific ingredients (e.g., user interface components). But ultimately, such environments have a textual interface for specifying the details. So, a program transformation system needs to deal with programs that are in text format.
However, for all but the most trivial transformations, a structured, rather than a textual, representation is needed. Working directly on the textual representation does not give the transformation enough information about what the text actually means. To bridge the gap between the textual and the structured representation, parsers and unparsers are needed. Also, we need to know how this structured representation is actually structured.
The syntactical rules of a programming language are usually expressed in a context-free grammar. This grammar (or syntax definition) of a programming language plays a central role in Stratego/XT. Most of the XT tools work on a grammar in one way or another. The grammar is a rich source of information. For example, it can be used to generate a parser, pretty-printer, disambiguator, tree grammar, format-checker, and documentation. This central role of a grammar is the most crucial aspect of XT, which is illustrated in Figure 3.2: all the components of a transformation system are directly or indirectly based on the grammar of a programming language.
What makes this all possible is the way syntax is defined in Stratego/XT. Stratego/XT uses the SDF language for syntax definition, which is a very high-level and declarative language for this purpose. SDF does not require the programmer to encode all kinds of properties of a programming language (such as associativity and priorities) in a grammar. Instead, SDF has declarative, concise, ways of defining these properties in such a way that they can actually be understood by tools that take the grammar as an input. And, of course, creating a grammar in such language is much more fun!
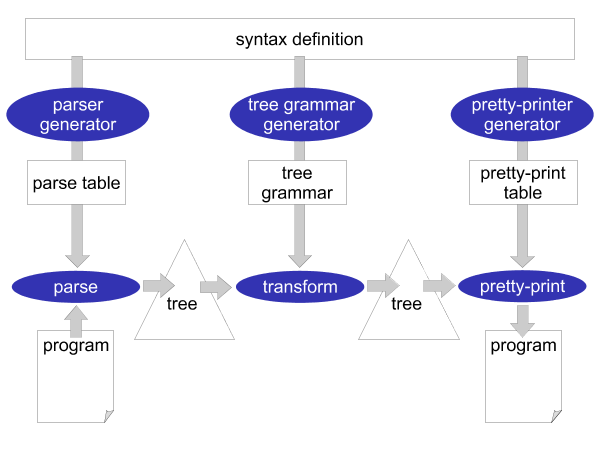
As mentioned before, the XT tools exchange a structured representation of a program: an abstract syntax tree. The structure of this abstract syntax tree is called the abstract syntax, as opposed to the ordinary textual syntax, which is called the concrete syntax. In XT, the abstract syntax is directly related to the syntax definition and can be generated from it. The result is a tree grammar that defines the format of the trees that are exchanged between the transformation tools. From the world of XML, you are probably already familiar with tree grammars: DTD, W3C XML Schema and RELAX NG are tree grammars in disguise.
Until now, we have been a bit vague about the format in which abstract syntax trees are actually exchanged between transformation tools. What is this structured program representation?
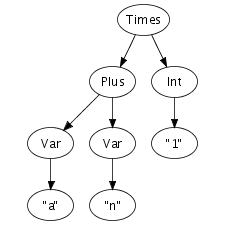
We can easily imagine an abstract syntax tree as a graphical
structure. For example, the tree at the right is a simple
abstract syntax tree for the expression (a + n) *
1. This representation corresponds closely to the
representation of trees in computer memory. However, drawing
pictures is not a very effective way of specifying tree
transformations. We need a concise, textual, way to express an
abstract syntax tree. Fortunately, there is a one-to-one
correspondence between trees and so-called first-order prefix
terms (terms, for short). A term is a constructor, i.e., an
identifier, applied to zero or more terms. Strings and integer
constants are terms as well. Thus, the following term
corresponds to the abstract syntax tree that we have just drawn.
Times(Plus(Var("a"), Var("n")), Int("1"))
In Stratego/XT, programs are exchanged between transformation tools as terms. The exact format we use for terms, is the Annotated Term Format, or ATerms for short. We will discuss this format in more detail later, but some of its features are interesting to note here.
First, ATerms are not only used to exchange programs between tools. ATerms are also used in the Stratego language itself for the representation of programs. In other words, ATerms are used for the external representation as well as the internal representation of programs in Stratego/XT. This is very convenient, since we don't have to bind the ATerms to Stratego specific data-structures. Usually, if such a data-binding is necessary, then there is always a mismatch here and there.
Second, an important feature of the implementation is that terms are represented using maximal sharing. This means that any term in use in a program is represented only once. In other words, two occurrences of the same term will be represented by pointers to the same location. This greatly reduces the amount of memory needed for representing programs.