Table of Contents
Imagine finding yourself in a situation where you have a collection of files containing source code. If this is an unreasonable prospect for you, stop reading and pick another tutorial. If you are still with us, consider these files the blueprints for your software. They are still not the award-winning, executable program you are aiming for, but by applying a compiler to them, you can generate one (with some minor provisions about syntactial and semantical correctness). If so inclined, you may also run a documentation generator like Javadoc on the source, to generate structured documentation. Or, while colleagues are not looking, you can secretly invoke tools like lint (C/C++) or FindBugs (Java) to weed out common programming errors.
The compilation, documentation generation and source-code analysis are all examples of software transformations , but they are certainly not the only ones. Software transformation has been used by the mathematically inclined for generating programs from high-level specifications, by forgetful people to recover lost design and architecture from legacy code and by reverse-engineers to obtain high-level, readable code from binary files after somebody accidentally misplaced a stack of backup tapes. Specialization of a program to known inputs in order to improve performance, optimization using domain knowledge from the application domain and improving program understanding by analysing sources are also favoured topics among software transformers.
But who uses software transformation, anyway? People with a problem resembling any in Figure 1.1 are. Compilation, the translation of a program to machine code in order to make it executable, is the standard processing technique applied to get running programs out of source code. But much more can be done. There are many other kinds of processes that can be applied to programs. For example, programs can be synthesized from high-level specifications; programs can be optimized using knowledge of the application domain; documentation for understanding a program can be automatically derived from its sources; programs can be specialized to known inputs; application programs can be generated from domain-specific languages; low-level programs can be reverse engineered into high-level programs.
All too often, Real Programmers facing such problems are of the opinion that software transformation is overly complicated dark magic, and that simple regular expression hacks solve the problem just fine. Almost equally often, their ad-hoc, text-based solutions turn out to be brittle, overly complicated and acquire a status of dark magic, with the result that no other team member dears touch the stuff. Most of the time, the problem would be easily solved in a maintainable and robust way if only the right tool could be found.
Figure 1.1. Applications of Software Transformation.
Compilers
-
Translation, e.g. Stratego into C
Desugaring, e.g. Java's
foreachintoforInstruction selection
-
Maximal munch
BURG-style dynamic programming
Optimization
-
Data-flow optimization
Vectorization
GHC-style simplification
Deforestation
Domain-specific optimization
Partial evaluation
Type checking
Specialization of dynamic typing
Program generators
-
Pretty-printer and signature generation from syntax definitions
Application generation, e.g. data format checkers from specifications
Program migration
-
Grammar conversion, e.g. YACC to SDF
Program understanding
-
Documentation generation, e.g. API documentation for Stratego
Document generation/transformation
-
Web/XML programming (server-side scripts)
So what do should you do if you have a mountain of source code that you have to do some transformation on? Obviously, using the the right tool for the job is a good start. We don't recommend using toothpicks to move software mountains. Instead, we think using Stratego for this is a good idea. In this tutorial, we will use small, understandable and cute examples that you can try out in the leisure of your own desktop. We hope these will convince you exactly how good an idea using Stratego for software transformation really is.
Stratego/XT is a framework for implementing software transformation systems. A software transformation system is usually organized as a simple pipeline of transformation steps, see Figure 1.2. At the source of the pipeline (far left), a parser reads the text of the input program and turns it into a parse tree or abstract syntax tree. Subsequently, one or several transformations components modify the tree. At the sink of the pipeline (far right), a pretty-printer turns the output tree into program text. The output program need not be in the same language as the input program. It need not even be a programming language. This allows us to create important tools such as compilers and documentation generators using Stratego/XT.
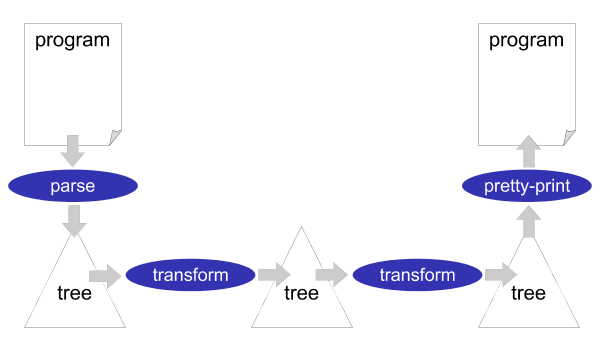
The Stratego/XT framework consists of two parts: Stratego, a language for implementing software transformations, and XT, a collection of transformation tools. The Stratego language is a powerful language for implementing the core transformations of a complete transformation system. The XT tools help with the implementation of the infrastructure required around these core transformations, such as a parser and a pretty-printer.
Stratego and XT aim at better productivity in the development of transformation systems through the use of a high-level representations of programs, domain-specific languages for the development of parts of a transformation system, and generating various aspects of a transformation system automatically.
The main ingredients of Stratego/XT are:
- ATerm Format
-
Although some transformation systems work directly on text, in general a textual representation is not adequate for performing complex transformations. Therefore, a structured representation is used by most systems. Since programs are written as texts by programmers, parsers are needed to convert from text to structure and unparsers are needed to convert structure to text.
The basic assumptions in our approach are that programs can be represented as trees, or terms, and that term rewrite rules are an excellent way to formalize transformations on programs. Stratego/XT uses the Annotated Term Format, or ATerms for short, as term representation. The Stratego run-time system is based on the ATerm Library which provides support for internal term representation as well as their persistent representation in files. This makes it easy to provide input and output for terms in Stratego, and to exchange terms between transformation tools.
- Stratego Language
-
Stratego is the core of Stratego/XT. It is a language for software transformation based on the paradigm of rewriting strategies. Basic transformations are defined using conditional term rewrite rules. These are combined into full fledged transformations by means of strategies, which control the application of rules.
Term rewrite systems are formalisations of systematic modifications of terms or trees. A rewrite rule describes how a program fragment matching a certain pattern is transformed into another program fragment. Term rewriting is the exhaustive application of a set of rules to a term.
A complex software transformation is achieved through a number of consecutive modifications of a program. At least at the level of design it is useful to distinguish transformation rules from transformation strategies. A rule defines a basic step in the transformation of a program. A strategy is a plan for achieving a complex transformation using a set of rules.
Figure 1.3. file: sample-rules.str
rules InlineF : |[ let f(xs) = e in e'[f(es)] ]| -> |[ let f(xs) = e in e'[e[es/xs]] ]| InlineV : |[ let x = e in e'[x] ]| -> |[ let x = e in e'[e] ]| Dead : |[ let x = e in e' ]| -> |[ e' ]| where <not(in)> (x,e') Extract(f,xs) : |[ e ]| -> |[ let f(xs) = e in f(xs) ]| Hoist : |[ let x = e1 in let f(xs) = e2 in e3 ]| -> |[ let f(xs) = e2 in let x = e1 in e3 ]| where <not(in)> (x, <free-vars> e2)
For example, consider the transformation rules above. TheInline*rules define inlining of function and variable definitions. TheDeadrule eliminates an unused variable definition. TheExtractrule abstracts an expression into a function. TheHoistrule defines lifting a function definition out of a variable definition if the variable is not used in the function. Using this set of rules, different transformations can be achieved. For example, a constant propagation strategy in an optimizer could use theInlineVandDeadrules to eliminate constant variable definitions:let x = 3 in x + y -> let x = 3 in 3 + y -> 3 + y
On the other hand, the
ExtractFunctionstrategy in a refactoring browser could use theExtractandHoistrules to abstract addition withyinto a new function and lift it to top-level.let x = 3 in x + y -> let x = 3 in let addy(z) = z + y in addy(x) -> let addy(z) = z + y in let x = 3 in addy(x)
Conceptually, rules could be applied interactively by a programmer via a graphical user interface. In Stratego/XT, you can use the Stratego Shell for doing this. More on this later. The problem with such interative manipulations is that the transformation is not reproducible, since the decisions have not been recorded. We want to be able to automate the transformation process, because we can then apply series of basic transformations repeatedly to a program. By generalizing the sequence of transformations, the combined transformation can be applied to many programs. This requires a mechanism for combining rules into more complex transformations, and this is exactly what the Stratego language gives us.
Pure term rewriting is not adequate for the implementation of software transformation systems, since most rewrite systems are non-confluent and/or non-terminating. Hence, standard rewriting strategies are not applicable. The paradigm of programmable rewriting strategies solves this problem by supporting the definition of strategies adapted to a specific transformation system. This makes it possible to select which rule to apply in which transformation stage, and using which traversal order.
- SDF Language
-
Converting program texts to terms for transformations requires parsers. Since Stratego programs operate on terms, they do not particularly care about the implementation of parsers. Thus, parsers can be implemented with any parsing technology, or terms can be produced by an existing compiler front-end. In practice, Stratego is mostly used together with the syntax definition formalism SDF. The Stratego compiler itself uses SDF to parse Stratego programs, and many Stratego applications have been developed with SDF as well.
The syntax definition formalism SDF supports high-level, declarative, and modular definition of the syntax of programming languages and data formats. The formalism integrates the definition of lexical and context-free syntax. The modularity of the formalism implies that it is possible to easily combine two languages or to embed one language into another.
- GPP and the Box Language
-
Stratego/XT uses the pretty-printing model provided by the Generic Pretty-Printing package GPP. In this model a tree is unparsed to a Box expression, which contains text with markup for pretty-printing. A Box expression can be interpreted by different back-ends to produce formatted output for different displaying devices such as plain text, HTML, and LATEX.
- XT tool collection
-
XT is a collection of transformation tools providing support for the generation of many infrastructural aspects of program transformation systems, including parsers, pretty-printers, parenthesizers, and format checkers.
- XTC
-
Parsers, pretty-printers, and transformations can be encapsulated in separate executable components, which can be reused in multiple transformation systems. Composition of such components is facilitated by the XTC transformation tool composition library. Initially this tutorial uses separate components that are glued using shell scripts, in order to improve the understanding of the separate components. The use of XTC is introduced later on.
Exactly what all this means will become clear to you as we move along in this tutorial.
This tutorial is divided into three parts. The first part introduces the XT architecture and many of the tools from the XT collection. An important point in this part that is how to construct parsers using the syntax definition formalism SDF. The parser takes source code text into structured ATerms. Another point in this part is the reverse action: going from ATerms back to source code text.
The second part of the tutorial introduces the Stratego language, starting with the concept of terms and moving on to rules and strategies. After explaining how rules and strategies may be combined to create complete transformation programs, the more advanced topics of concrete syntax and dynamic rules are covered.
The third and final part of the tutorial explains the most important strategies found in the Stratego library: basic data types such as lists, strings, hashtables and sets; basic I/O functionality; the SUnit framework for unit testing. This part also explains the technical details of how to put together complete software transformation systems from XT components using the Stratego build system, using the XTC component composition model.
Table of Contents
The Stratego/XT project distributes several packages. So let's first make clear what you actually need to install. Stratego/XT itself is a language independent toolset for constructing program transformation systems. Language-specific extensions of Stratego/XT are distributed as separate packages, so that you only have to install what you really need for your particular application.
Stratego/XT.
All Stratego/XT users need to install the ATerm Library
(aterm), the SDF2 Bundle
(sdf2-bundle) and Stratego/XT
(strategoxt). These packages enable you to
compile Stratego programs, and provide the basic
infrastructure for parsing and pretty-printing source files.
Stratego Shell. Optionally, you can install the Stratego Shell, which provides an interpreter for Stratego and an interactive command-line for experimenting with the Stratego language. The Stratego Shell is used in the Stratego part of this tutorial to demonstrate the features of the Stratego language. The Stratego Shell is also very useful for small experiments with strategies of the Stratego Library.
Extensions. Then there are the language-specific packages. These packages provide the basic infrastructure for parsing, pretty-printing, and in some cases also analyzing source files of a specific programming language. Reusing such a package enables you to get started immediately with the implementation of an actual transformation. Examples of such packages are Java-front, Dryad, Transformers C and C++, BibTeX Tools, Prolog Tools, AspectJ Front, and SQL Front. Also, there are some demonstration packages, for example Tiger Base, which implements a compiler for the Tiger language, and Java Borg, which demonstrates the implementation of language embeddings. All these packages can separately be installed as extensions of Stratego/XT.
Examples of the Stratego/XT Manual. All the code examples in this manual are available for separate download, so that you can experiment based on these: examples.tar.gz
First of all, you have to decide which deployment mechanism you want to use. For users of RPM-based Linux distributions (such as Redhat, Fedora Core, and SUSE), we advise to use RPMs, which are available from the release page. For Cygwin users we provide pre-compiled binaries that can simply be unpacked. For Mac OS X users, we provide these binary packages as well, but they can also use the Nix deployment system, which will guarantee that all dependencies are installed correctly. Nix packages are also available for Linux users. Finally, it is always possible to build from source.
Next, download the required packages. Stratego/XT depends on the
ATerm Library and the SDF2 Bundle, so you have to download
aterm, sdf2-bundle, and
strategoxt. The downloads are all available at the
release page of Stratego/XT.
The following sequence of commands takes care of building
and installing the aterm and the sdf2-bundle in
/usr/local.
$tar zxf aterm-version.tar.gz$cd aterm-version$./configure$make$make install$cd ..$tar zxf sdf2-bundle-version.tar.gz$cd sdf2-bundle-version$./configure --with-aterm=/usr/local$make$make install$cd ..
If you want to install the packages at a different
location (i.e. not /usr/local, you
should specify a --prefix in the configure
command. For example:
$./configure --prefix=/opt/aterm$./configure --prefix=/opt/sdf2-bundle --with-aterm=/opt/aterm
In this case, it possible that the sdf2-bundle cannot find
the aterm package. To tell the sdf2-bundle where it should
look for the ATerm Library, you can use the
--with-aterm argument:
$ ./configure --prefix=/opt/sdf2-bundle --with-aterm=/opt/aterm
Alternatively, you can add the location of the ATerm
Library to the PKG_CONFIG_PATH, which the
configure script will use for searching packages. In this
way, you don't need to specify the --with-
arguments. More information about this is available in the
pkg-config documentation (man
pkg-config). For example:
$ export PKG_CONFIG_PATH=/opt/aterm/lib/pkgconfig:/opt/sdf2-bundle/lib/pkgconfig
Unpack, configure, make and install Stratego/XT using the following commands:
$tar zxf strategoxt-version.tar.gz$cd strategoxt-version$./configure --with-aterm=/usr/local --with-sdf=/usr/local$make$make install
If you want to install StrategoXT at a different prefix,
you should specify a --prefix. If you
installed the ATerm Library and the SDF2 Bundle at a
different location, you should specify their location
using --with-aterm and
--with-sdf. For example:
$ ./configure --prefix=/opt/strategoxt \
--with-aterm=/opt/aterm --with-sdf=/opt/sdf2-bundle
As mentioned earlier, you can alternatively add the
location of the ATerm Library and the SDF2 Bundle to the
PKG_CONFIG_PATH, which the configure script
will use for searching packages.
The Stratego Shell, Java Front, Tiger Base and several other packages depend on Stratego/XT. For all these packages, you can use the following commands:
$tar zxfpackage-version.tar.gz$cdpackage-version$./configure$make$make install
For all these packages, you should use the
--with-aterm=,
dir--with-sdf=,
and
dir--with-strategoxt=
options if you installed these packages at non-standard
locations. Alternatively, you can extend the
dirPKG_CONFIG_PATH to include the locations of
the ATerm Library, SDF2 Bundle, and Stratego/XT.
Installing binary RPMs is very easy. Install the RPMs by
running rpm -i * in the directory where you
have downloaded the RPMs. Use the upgrade option rpm
-U * if you have already installed earlier versions
of RPMs for aterm, strategoxt or the sdf2-bundle. Of course
you can also install the RPMs one by one by specifying the
filenames of the RPMs.
Using the Nix deployment system for the installation of Stratego/XT is a good idea if you need to run multiple versions of Stratego/XT on the same system, if you will need to update other Stratego/XT related packages regularly, or if there is a problem with installation from source at your system. The Nix deployment system is designed to guarantee that the Stratego/XT that we are using on our system is exactly reproduced on your system. This basically guarantees that the installation will never fail because of missing dependencies or mistakes in the configuration.
The release page of all the packages refer to Nix packages
that can be installed using
nix-install-package.